

Este é o primeiro de uma série de artigos contando como foi a adoção de containers pela Globo.com. O conteúdo da série é baseada em uma palestra realizada na QCon São Paulo 2018.
A globo.com possui mais de 1800 aplicações utilizando um total de 4600 containers em mais de 600 máquinas virtuais e mais de 500 desenvolvedores realizam centenas de deploys diariamente. A plataforma que torna isso tudo possível é desenvolvida e mantida por um time de menos de 10 pessoas. Incrível né?
É claro que isso nem sempre foi assim. Para saber como chegamos aqui é necessário entender o contexto que a empresa se encontrava em 2012.
O contexto (pré 2012)
Em 2012 a realidade da Globo.com era bem diferente. As aplicações rodavam em máquinas físicas, o que demandava um alto tempo de setup dos ambientes além de acarretar um desperdício imenso de recursos.
Além disso, os times eram responsáveis por manter seus scripts de deploy e ferramentas de provisionamento de dependências próprios. Tais scripts eram bastante específicos, dificultando o compartilhamento entre os diferentes times.
Como os times de desenvolvimento não eram responsáveis por todo o processo de deploy de sua aplicação, era necessário passar por um processo de aprovação para todas as mudanças e agendar o deploy do produto. Com isso, os times faziam em média 1 deploy a cada duas semanas.
Essas condições acarretavam o surgimento de aplicações monolíticas, pouca inovação e um alto custo de infraestrutura.
O início (2012)
Em 2012 um time foi criado com o intuito de repensar e melhorar todo o processo de criação e deploy de aplicações dentro da Globo.com. Os objetivos principais eram abstrair a infraestrutura e dar poder ao desenvolvedor, de forma que ele pudesse ser dono de todo o processo de sua aplicação.
Algumas premissas foram levadas em consideração na hora de buscar ferramentas existentes que atendessem nossos objetivos:
- Open Source;
- Extensível, de forma que fosse simples adicionar novos componentes e customizar para as necessidades específicas da globo, sem ser preciso manter um fork;
- Suporte a multíplas linguagens, pois a globo sempre foi uma empresa com projetos em diversas linguagens de programação;
- Alta disponibilidade: as aplicações rodando na plataforma não poderiam ser impactadas por problemas na própria plataforma;
- Escalável: deve ser possível escalar a quantidade de deploys, aplicacões e é claro, a quantidade de acessos as aplicações;
- Simples: não queremos dificultar a vida dos desenvolvedores.
Queríamos uma experiência semelhante à do Heroku, porém utilizando nossa própria infraestrutura e com uma ferramenta que atendesse todos os requisitos acima. Essas plataformas são conhecidas como Plataformas como Serviço (Platform as a Service, ou PaaS).
O ecossistema em 2012 era muito diferente de hoje. Ainda não existia Kubernetes, Swarm e outros orquestradores. Não existia nem o Docker, que foi o responsável por popularizar os containers! Com isso, nenhuma das poucas ferramentas existestes atendiam nossos requisitos. Tomamos a difícil decisão de construir nosso PaaS do zero!
E assim nasce o Tsuru (2012)

O tsuru é um PaaS de código aberto, criado a partir das premissas definidas anteriormente e inspirado no Heroku. Escrito em Go, tem como principal objetivo facilitar o deploy de aplicações.
Com alguns poucos comandos os desenvolvedores são capazes de criar uma nova aplicação, fazer deploy de um código e escalar a aplicação a fim de atender as requisições. Tudo isso sem precisar interagir com scripts de deploy, provisionamento e nem Dockerfiles! O conceito de containers não é exposto para o desenvolvedor; tudo que ele precisa é do seu código e de suas dependências!
A primeira versão do tsuru utilizava máquinas virtuais (com o juju) para fazer o deploy da aplicação. O motivo para isso é bem simples: em 2012 ainda não existia o Docker! Containers ainda eram uma tecnologia pouco conhecida e, principalmente, não existia uma forma fácil de compartilhar e distribuir os containers (isso só foi possível a partir da criação das docker images).
Mesmo utilizando máquinas virtuais, o tsuru foi capaz de reduzir o tempo de primeiro deploy de uma nova aplicação para cerca de 40 minutos. Deploys subsequentes levavam cerca de 5 minutos.
O fim de 2012 chegou e já tinhamos uma aplicação rodando em produção na Amazon Web Services (AWS).
Habemus Docker (2013)
Estavamos bastante felizes com a diminuição no tempo de deploy das aplicações porém queriamos ainda mais. Além disso, após o primeiro deploy todos os deploys seguintes eram aplicados em cima da máquina virtual atual. Ou seja, não eram reproduzíveis e o estado das diferentes máquinas virtuais poderiam divergir do estado desejado.
Começamos então a construir uma prova de conceito utilizando Linux Containers. Parecia ser uma solução promissora, porém muitas coisas precisavam ser construídas para que pudessemos orquestrar essas containers. Foi aí que, em Março de 2013, o Docker foi lançado.
Com o docker tinhamos em mãos uma API em cima dos Linux containers e as docker images para que fosse possível distribuir as aplicações. Com isso, cada deploy da aplicação cria uma nova camada na imagem da aplicação e conseguimos ter deploys rápidos (o startup e a distribuição dos containers é muito mais rápida do que com as VMs) e reproduzíveis.

Apesar do Docker resolver diversos dos nossos problemas, ainda existia uma questão não respondida: como escolher em quais máquinas virtuais rodar os containers? Ou seja, como orquestrar os containers? Para isso, tivemos que criar nosso próprio orquestrador de containers, o docker-cluster.
Podemos pensar no docker-cluster como um Docker distribuído: dizemos para ele quantos containers de uma aplicação rodar, em qual conjunto de nós e ele é reponsável por melhor distribuir essas aplicações. Bem parecido com o que o Kubernetes, Swarm e outros orquestradores de containers fazem!
Vamos a um exemplo. Digamos que queremos escalar uma aplicação do cartola adicionando 3 novas units. Units correspondem a uma unidade computacional de uma aplicação e nesse caso específico são análogas aos containers.

Na imagem acima podemos visualizar 4 nós (VMs) diferentes: N1, N2, N3 e N4. Neste exemplo cada nó possui 2 metadados diferentes: pool e zone. O primeiro passo feito pelo docker-cluster é remover os nós que não são do pool utilizado pela aplicação (que, neste exemplo, é o pool de esporte). Logo, os nós N2, N3 e N4 são os candidatos a receberem as novas units.
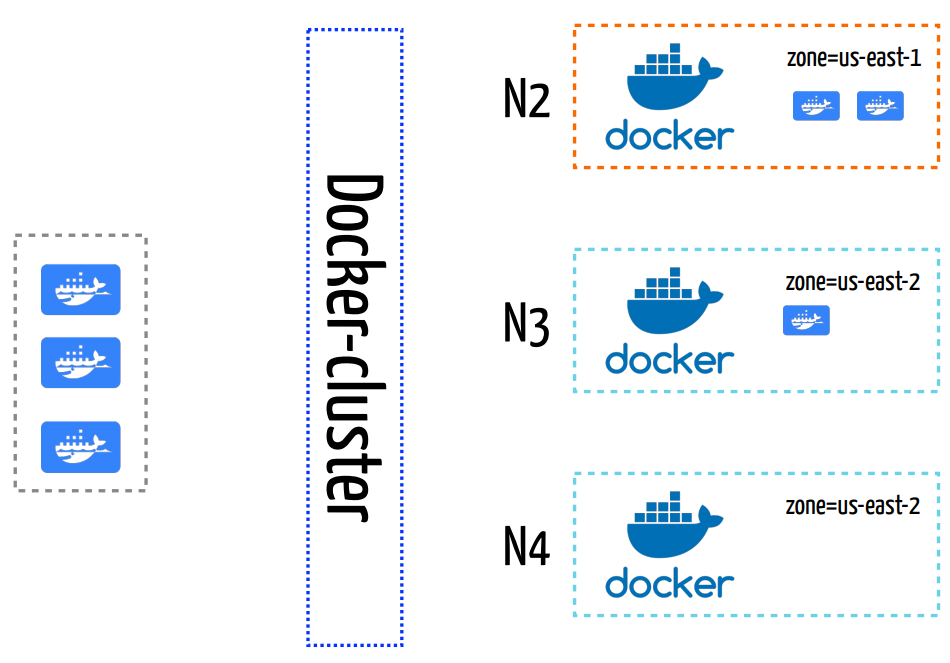
Os nós selecionados já possuem outros 3 containers sendo executados (dois no N2 e um no N3). O docker-cluster irá selecionar os nós que deverão executar os novos containers levando em consideração a distribuição atual entre os nós e entre os metadados diferentes (nesse caso, o zone). Essa heurística é utilizada de forma a diminuir o impacto de problemas em zonas e nós específicos da cloud. Dessa forma, conseguimos garantir a alta disponibilidade das aplicações.
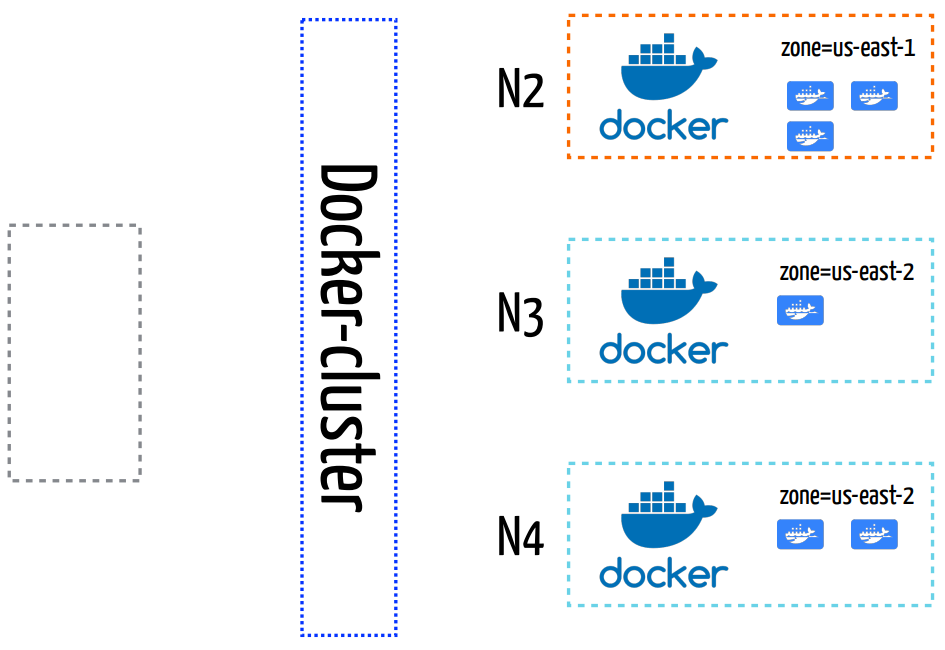
A distribuição final pode ser vista na imagem acima. A aplicação possui 3 containers em cada uma das zonas de disponibilidade (us-east-1 e us-east-2).
Chegamos ao final de 2013 com uma aplicação em produção utilizando Docker com VMs pré-provisionadas na AWS.
E com isso, também chegamos ao final do primeiro post da série. No próximo post vamos falar sobre como expandimos a oferta de serviços disponíveis para as aplicações e como escalamos nosso próprio time para dar vazão a crescente número de usuários desenvolvedores.

André muito bom o post! Bem legal mesmo!!
CurtirCurtir